How a modern data platform enables automated transparency
Nov 07, 2022
- IT
- SAP
- Microsoft Azure
- data
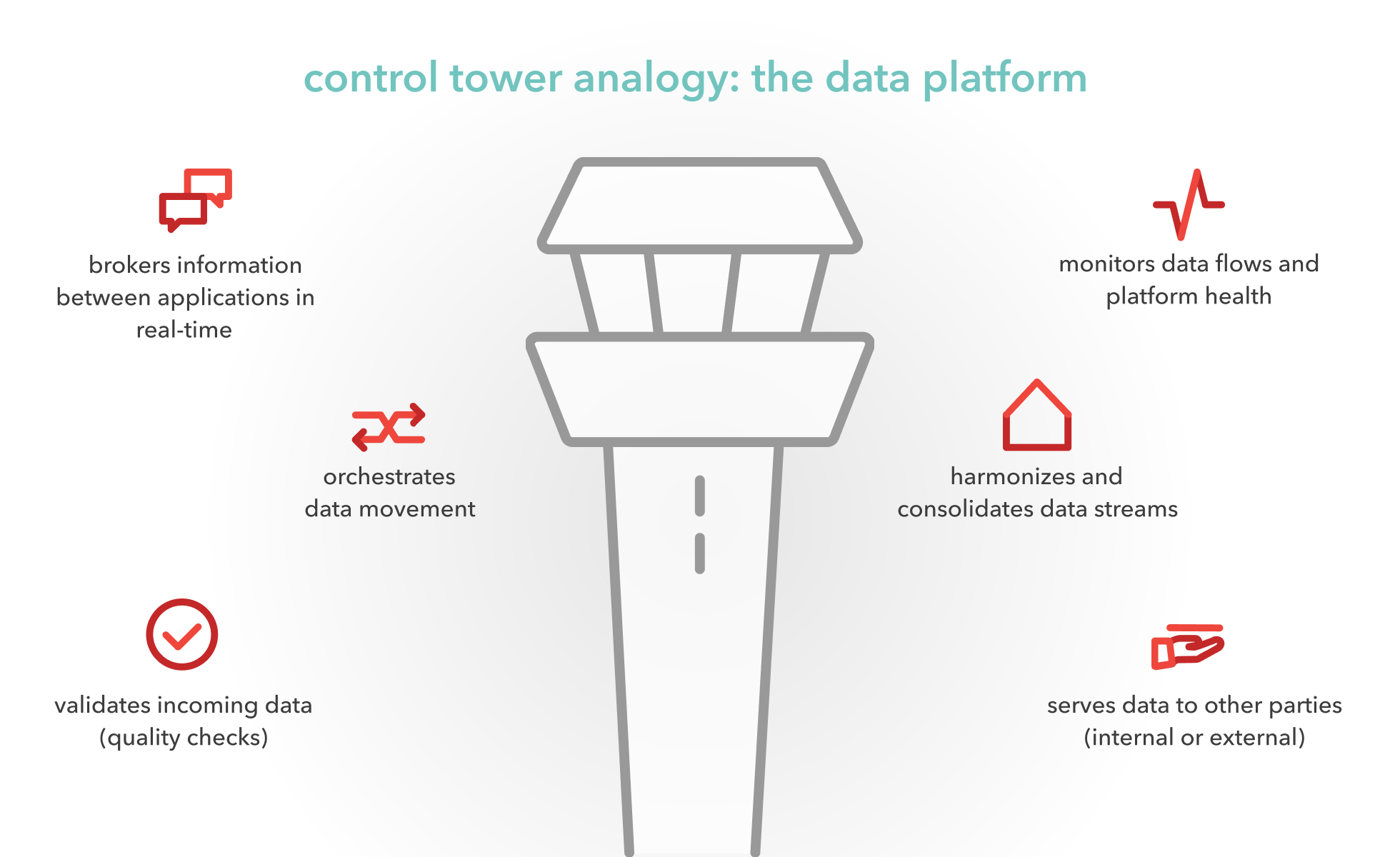
In recent years, ‘data transparency’ has gained a lot of attention. And it’s not hard to see why: with data playing a decisive role in our lives, we demand to know where information comes from and whether we can trust it. Organisations need to keep a clear overview of all the data they’re collecting as well: not just for compliance, but also to tap into its full potential. Here's where a modern data platform can make all the difference.