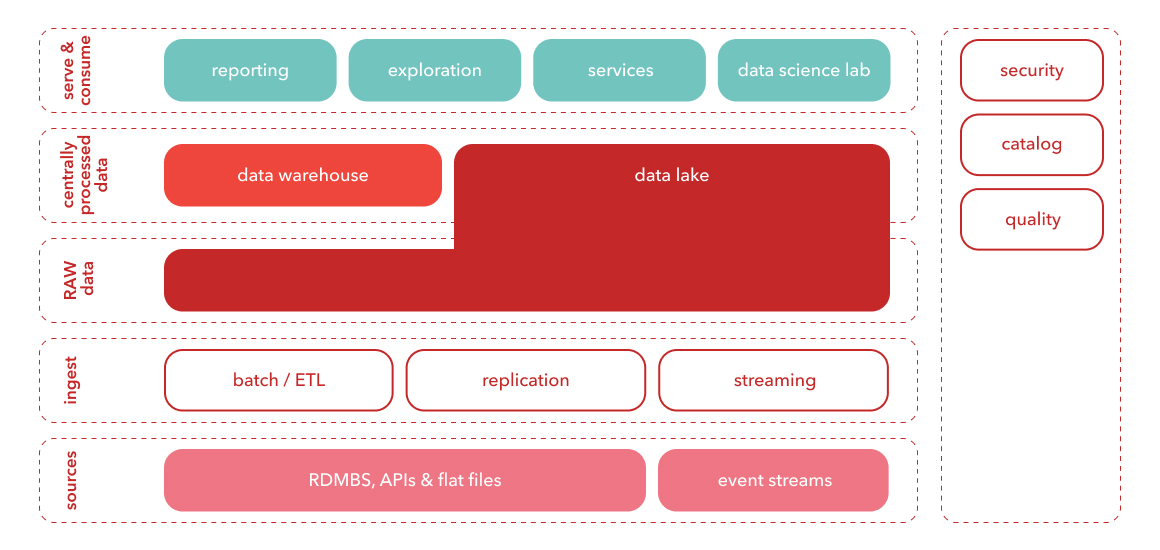
Combining the best of both worlds
Imagine a warehouse stocked with well-organized components in neat rows and stacks. Now, think of a lake, full to the brim with water, fish and other objects all jumbled together with no immediate order imposed on them. It’s relatively straightforward to find and access a specific object located in a warehouse – while it requires different processes to identify and extract specific content from a lake.
Like their namesakes, data lakes and data warehouses differ quite profoundly in how they store and process what fills them: information.
- A data warehouse deals best with moderate amounts of structured data, which is used mainly in reporting and service delivery.
- A data lakehouse is best at handling large amounts of raw and unstructured data, which is used mainly in data science, machine-learning exploration, and similar applications.
The main problem with this either/or approach? Today’s companies need to be able to handle all types data, and use them in all types of scenarios. In other words, having to choose between a data lake or warehouse is almost always a case of choosing the lesser evil. This is why many organizations now use both in tandem, leading to higher levels of complexity and duplicated data.
Enter the data lakehouse: an open architecture that combines the best features of – you guessed it – data lakes and data warehouses, with increased efficiency and flexibility as a result. Made possible by the rising trend of open and standardized system design, data lakehouses can apply the structured approach of a warehouse to the wealth of data contained in a data lake.
The main features of a data lakehouse
- Handle various data types: structured, unstructured and semi-structured.
- Enjoy simplified data governance and enforce data quality across the board.
- Get BI support directly on the source data, which means that BI users and data scientists work from the same repository;
- Benefit from increased scalability in terms of users and data sizes.
- Get support for data science, machine learning, SQL, and analytics – all in one place.




/data-as-asset-720x360-(1).webp?mode=autocrop&w=1000&h=750&attachmenthistoryguid=93bf9d6c-d497-4982-a2f1-997d80354ae6&v=&focusX=117&focusY=142&c=a91bdceeb91cdb02402081f7733dd7c4ffe0a26db8684ad1aa399831691396d0)
