Le meilleur des deux mondes ensemble
Représentez-vous un entrepôt contenant des composants bien rangés en lignes et en piles bien ordonnées. Imaginez maintenant un lac, plein à ras bord d’eau, de poissons et d’autres objets, tous pêle-mêles, sans aucun ordre apparent. Trouver et atteindre un objet spécifique stocké dans un entrepôt est relativement simple ; identifier et récupérer un contenu spécifique dans un lac nécessite en revanche des traitements différents.
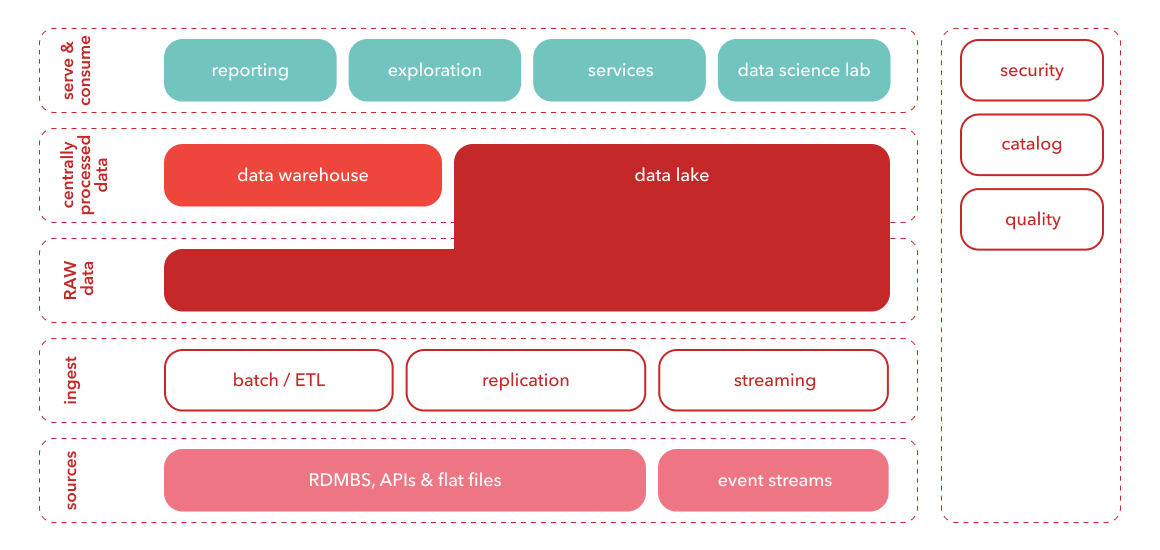
À l’instar du nom qui leur sert de support, les data lakes et les data warehouses se distinguent assez nettement par la manière dont ils stockent et traitent ce qui les remplit : l’information.
- Un data warehouse gère au mieux des quantités raisonnables de données structurées, utilisées principalement pour le reporting et la prestation de services.
- Un data lakehouse est plus apte à traiter de grandes quantités de données brutes et non structurées qui sont principalement utilisées dans la data science, l’exploration par apprentissage automatique et des applications similaires.
Une approche « soit, soit » représente-t-elle un problème prioritaire ? Les entreprises modernes doivent être en mesure de traiter tous les types de données et de les utiliser dans tous les types de scénarios. Choisir entre un data lake ou un data warehouse équivaut, donc, presque toujours à choisir le moindre. De nombreuses organisations utilisent désormais l’un et l’autre en tandem, entraînant des niveaux de complexité accrus et la duplication des données.
Le data lakehouse fait, alors, son apparition : une architecture ouverte qui combine les meilleures fonctionnalités - vous vous en doutez - des data lakes et des data warehouses, avec à la clé une efficacité et une flexibilité supérieures. La tendance grandissante en faveur d’une conception ouverte et normalisée des systèmes permet aux data lakehouses de recourir à l’approche structurée d’un warehouse pour traiter la masse de données contenue dans un data lake.
- traitez différents types de données : structurées, non structurées et semi-structurées ;
- profitez d’une data governance ;
- simplifiez et appliquez la data quality à tous les niveaux ;
- bénéficiez d’un support BI directement sur les données sources - les utilisateurs BI et les data scientists travaillent à partir du même référentiel ;
- tirez parti d’une évolutivité accrue quant aux utilisateurs et à la taille des données ;
- faites-vous accompagner dans la science des données, l’apprentissage automatique, le SQL et l’analytics - le tout en un seul endroit.

/Website_Landingpage_new_DataAnalytics_1920x355-(1).webp?mode=autocrop&w=1000&h=750&attachmenthistoryguid=03a251fc-2ae3-48b7-9c97-afd9a44e5f30&v=&focusX=964&focusY=231&c=baa1d18579ae86be77f8f7ba91249fce3adba2943d7986aa62311c2dc2b28119)
/blog3720x3601-(1).webp?mode=autocrop&w=1000&h=750&attachmenthistoryguid=c9c5aa60-e0a8-4c6d-a1c2-261395e6fad9&v=&focusX=1064&focusY=310&c=bc4dc12998f02c718723ecfe8374b15ceb7ff99e48afc21837e6301cb971c34a)
